Machine learning is fundamentally an optimization problem: we choose parameters to minimize a loss (or maximize an objective).
Minimizing f(x) is equivalent to maximizing -f(x).
Minimization and root-finding are closely connected: solving f(x)=0 can be written as minimizing f(x)^2.
A regression can be estimated directly (“by hand”) as an optimization of squared errors, which is often useful when you want custom or more robust objective functions.
Example:
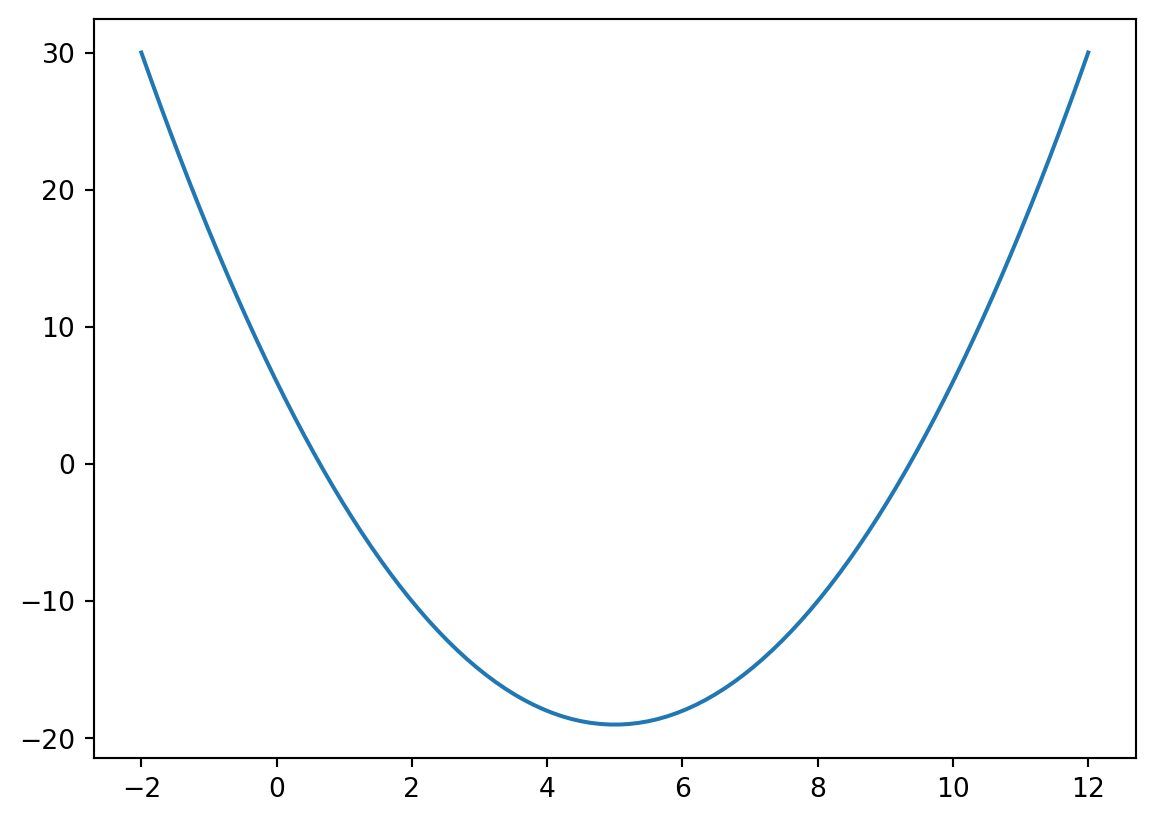
f(x) = x^2 - 10x + 6.
This simple convex function is only used to show how minimize works from different starting values.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.optimize import minimizeimport yfinance as yfimport warningswarnings.simplefilter(action='ignore', category=FutureWarning)def f(x):return x**2-10*x +6x = np.linspace(-2, 12, 100)plt.plot(x, f(x))res_left_start = minimize(f, [-100])res_right_start = minimize(f, [100])
Key result:
From start -100, optimizer converges to x^*=5.0.
From start 100, optimizer converges to x^*=5.0.
Minimum objective value is f(x^*)=-19.0.
In the full output objects (res_left_start and res_right_start), .x is the optimizer solution, .fun is the objective value at the solution, and .success reports convergence status.
Root-Finding via Minimization
One optimization-based way to find roots of f(x) is to minimize:
g(x) = f(x)^2.
If f(x)=0, then g(x)=0.
Why this works:
A square is always nonnegative, so g(x) \ge 0 for every x.
The minimum possible value of g(x) is therefore 0.
We get g(x)=0 exactly when f(x)=0, so if a root exists, any global minimizer with objective value 0 is a root.
This approach is useful as a unifying optimization view. In practice, dedicated root-finding methods can be more efficient when their assumptions are satisfied.